
三星解读先进封装 透露HBM未来
在日前OCP的一场演讲中,三星分享了他们对先进封装的观点。他们同时还透露,光将在其中扮演重要角色。下面,我们来总结一下三星这个演讲的重要内容,值得值得一提的是,三星在演讲中还透露了他们眼里的HBM未来。
为何需要先进封装?
在演讲的开始,三星首先讲述了为何需要先进封装。
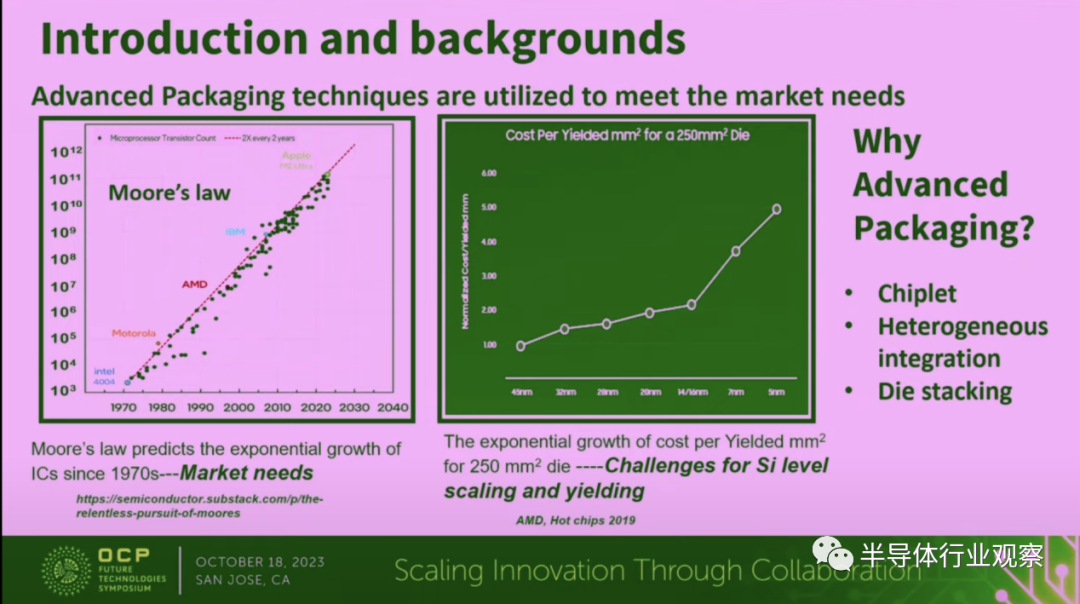
三星指出,如上图图左所示,在摩尔定律的指导下,芯片集成的晶体管数量几乎是每两年翻一番。但图右也提醒着每位芯片从业者,受限于各种因素,硅级别的缩放正在变得越来越艰难。而且,如果我们继续使用传统的方法去做晶体管微缩,成本会非常昂贵。
在这种情况下,先进封装对于半导体行业越来越重要。因为正是在先进封装的推动下,让Chiplet、异构集成和裸片堆叠成为了可能。先进封装也让开发者打造起更高良率的小芯片,同时还可以让客户根据需求为芯片选择相对应的制程,然后将他们集成到一起。
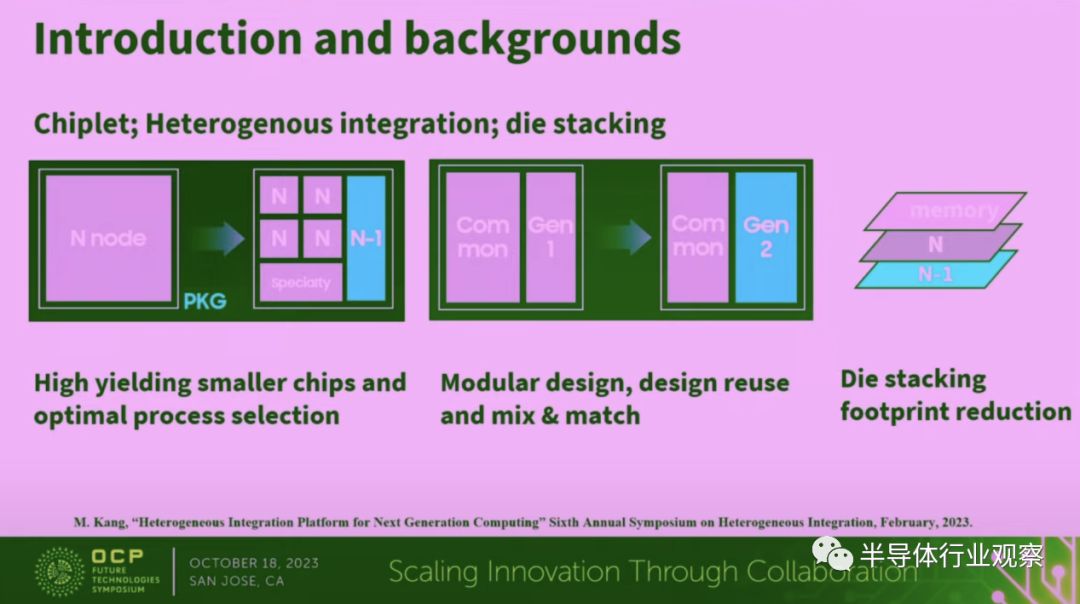
与此同时,开发者还可以用模组化设计,打造可以重复使用,且能混搭的芯片。至于裸片堆叠的方式,则能减少芯片的尺寸。
然而,在获得好处的同时,我们还是需要同时解决与之俱来的技术和逻辑等问题,才能拥有更好的异构集成。当中就包括了设计功耗和信号路由的多领域协同设计、热管理、促进为高速和低功耗Chiplet Die-to-Die(简称D2D)通信、UCIe、BoW和HBI等打造行业开放平台和标准化,以及在硅的安全性、KGD以及Chiplet的质量等多个方面建立并澄清协议。

三星演讲者在演讲中指出,D2D的内部互联也正在走向微缩,例如,Bump pitch正在朝着20 微米推进。与此同时,传统的TCB工艺正在逐渐被HCB工艺取替。因为后者能够提供更紧密的Bump pitch以及更小的bumps,而且在热管理方面也有很多优势。

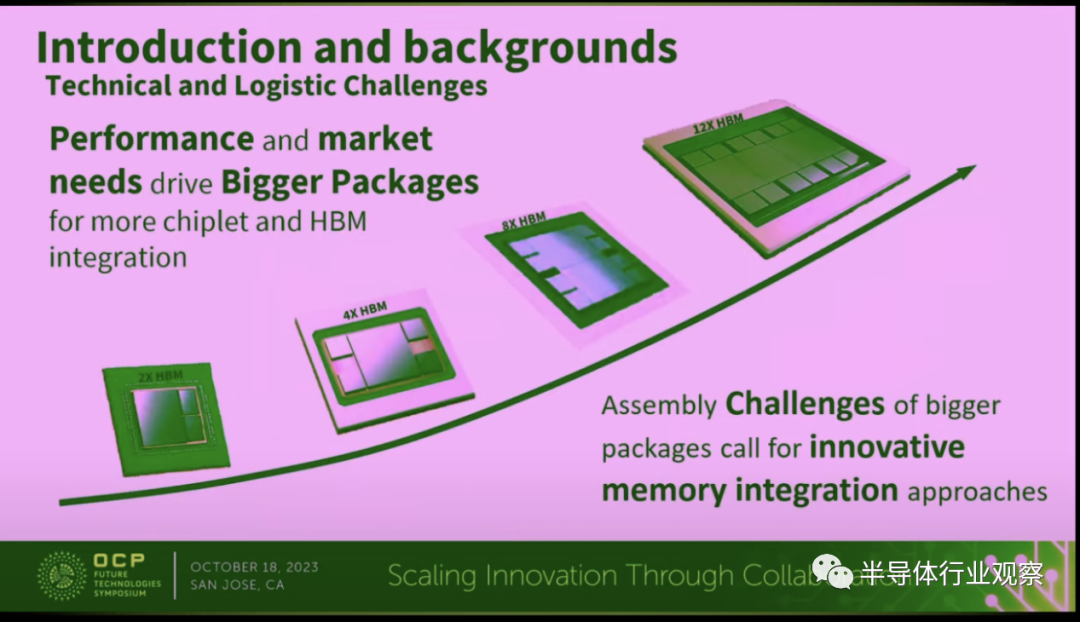
如下图所示,三星的演讲者认为,在性能和市场的推动下,我们希望在单个封装内集成更多的Chiplet和HBM。但随着封装变得越来越大,很多挑战也随之而来。为此,行业正在渴求新的存储集成方法,而不是像过往一样在平面平铺。
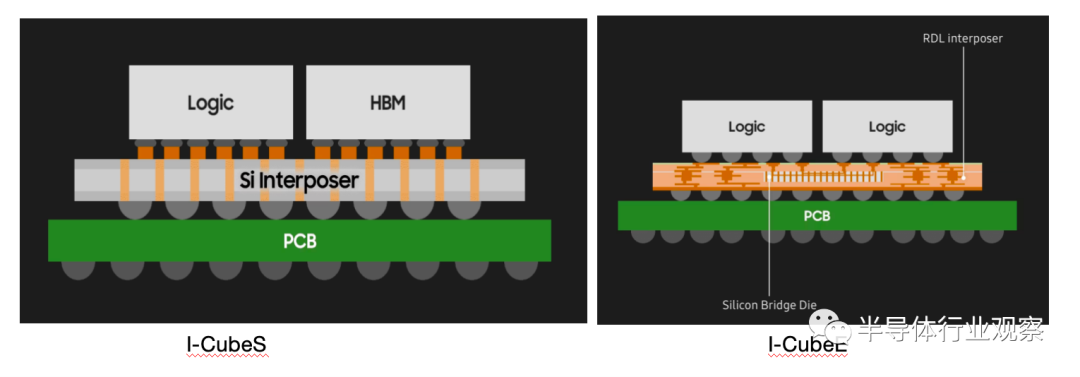
如下图所示,三星提供了包括2.5D和3D在内的丰富的先进封装交钥匙解决方案,涵盖了I-CubeS、I-CubeE、X-Cube (TCB) 和X-Cube (HCB)四个不同的封装类型。
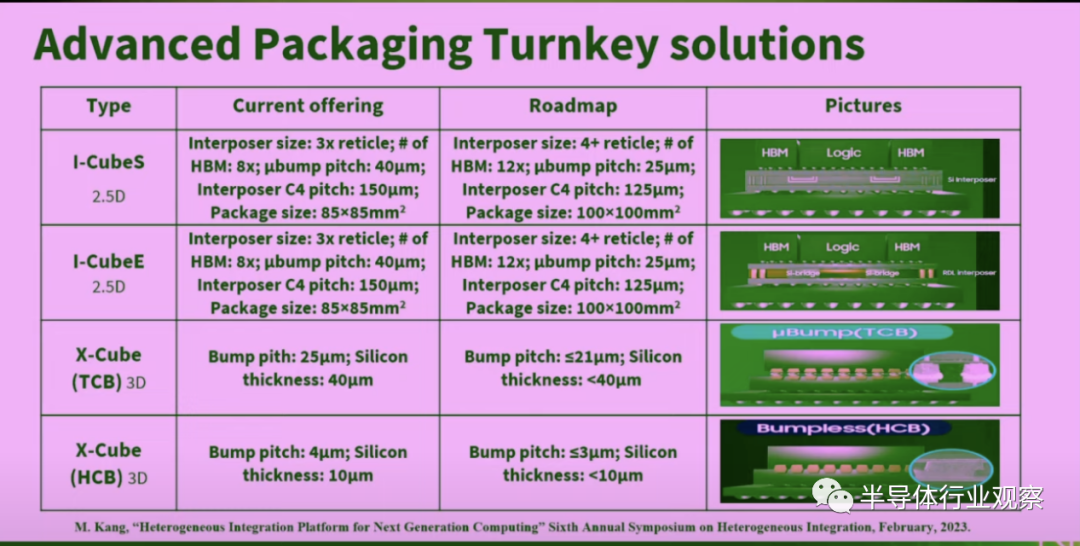
其中I-CubeS和I-CubeE均属于2.5D封装技术。I-CubeS和I-CubeE的技术特点是,在一个85x85mm²的封装内并行放置多个HBM(目前是8个),互连层尺寸为3x reticle(即互连层的面积是一个标准光罩曝光面积的三倍),微凸块间距为40µm,互连层C4间距为150µm。未来I-CubeS和I-CubeE的未来路线图是将互连层将扩大到4x reticle,HBM数量增至12个,微凸块间距减小至25µm;互连层C4间距缩小至125µm;封装尺寸将扩大至100x100mm²。
两者所不同的是结构,I-CubeS的结构是HBM和逻辑芯片布置在同一互连层上,使用大型的硅中介层,不过即使在使用大型互连层的情况下,也能够提供令人印象深刻的带宽和出色的性能能力。而I-CubeE采用硅嵌入式结构,通过应用FOPLP(即扇出面板级封装),结合了精密图案化的硅桥和无TSV结构的RDL互连层以及大尺寸互连层的优势。随着中介层尺寸变得更大,I-CubeE比使用硅中介层更具成本效益,但但仍能够利用嵌入在FOPLP中间的硅桥的小L/S(线宽/线距)优势,作为硅片间的接口。
X-Cube (TCB)和X-Cube (HCB)则代表了三星在3D封装领域的技术。X-Cube (TCB)和X-Cube (HCB)的区别是有无凸块连接技术。X-Cube (TCB)采用了25µm的微凸块间距和40µm的硅片厚度,而X-Cube (HCB)则展示了更高级的技术,具有只有4µm的微凸块间距和更薄的10µm硅片厚度,这表明了其在精密度上的提高。
整体来看,这些技术的发展预计将极大推动芯片封装的性能,使其在高性能计算领域得到更广泛的应用,同时也预示了未来封装技术向更高密度、更小间距发展的趋势。
HBM的未来走向
三星方面认为,如上文所说,随着封装变得越来越大,就带来了装配和可靠性等多方面的挑战。为此,三星通过提供一个在logic die上堆叠DRAM die(类似HBM的应用)的方法,将功耗效率提升了40%,并将延迟降低了10%。(下图左侧所示)
在另一种方案中,三星将Cash DRAM堆叠在logic die上,这种方案下,功耗效率提升了60%,延迟则降低了50%。在三星看来,这是一个更好的、面向未来解决方案。(下图右侧所示)

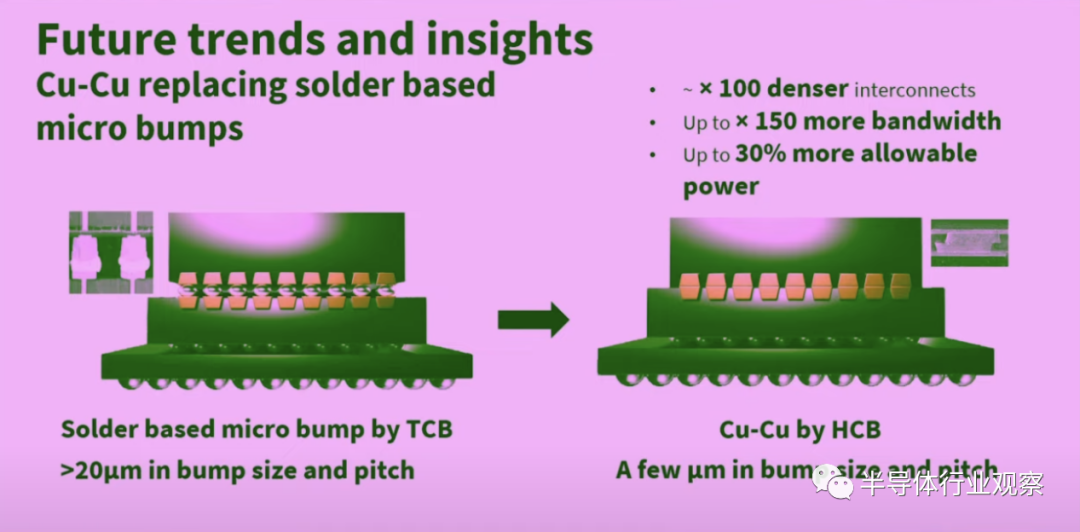
而在内部互联方面,如果在Bump pitch大于20μm的时候,可以使用基于TCB焊锡的微凸块。但展望未来,基于HCB的copper to copper bond则能带来更小的bump size、bump pitch。在这种方式下,三星能够将密度提升100倍,带宽也能提高150倍,功耗效率也能提升30%。
三星方面进一步指出,展望未来,光互连将发挥重要作用。众所周知,光子学是一项基于一种可以对单个光子(光的粒子/波)信息进行编码的技术,这意味着它几乎改善了我们当前计算环境中我们关心的一切。功耗大幅降低(发射的是光粒子而不是电子流),处理速度也得到提高(延迟达到飞秒级,传播速度接近光速极限)。但要实现这一目标需要工程、量子物理学和人类的聪明才智。
三星认为,在使用光学I/O后,将获得非常高的带宽密度;与此同时,这种解决方案还能带来非常低的功耗。在三星看来,光学I/O也是有两种实验方式:一种是是直接用光学I/O将逻辑和存储(包括HBM)连接起来;另一方面,则用光学I/O将逻辑封装和存储封装连接到一起。

具体来说,在第一种方案中,我们看到,光子介质层被安置在基础封装层和顶层之间。顶层不仅包括逻辑处理单元(比如GPU)还有高带宽存储器(HBM),它们通过这个光子介质层进行通信。然而,这个方案的成本相对较高,不仅需要引入这个中介层,还要采用光子I/O技术来实现本地逻辑处理单元和HBM之间的连接。
另一种方案则是将HBM存储与芯片封装完全解耦。这样,您就不必处理中介层带来的芯片封装复杂性(包括物流上的问题),而是将HBM模组从芯片本体分离出来,并通过光学技术与逻辑处理单元相连。这种方法简化了HBM和逻辑单元的芯片制造与封装成本,并且避免了复杂的数字到光学信号内部转换。
众所周知,最近两年,因为AI芯片的火热,带动了HBM走上了风口浪尖,关于这个技术的未来发展路线,在我们之前的文章《HBM 4,要来了》有了比较详细的介绍。而在更早之前的文章《HBM的崛起》,我们更是详细介绍了HBM的前世今生。
外媒Tomshardware直言,从某种角度看,三星的上述方法似乎是最合理的选择。但这同时意味着需要对服务器的设计规范进行更深入的重新思考。这种做法可能会促使“HBM memory cubes”(HMC,HBM存储立方体)的出现——即预先装载在特定光子接口上的HBM内存库。鉴于HBM已经与芯片本体解耦,并且假设维持了标准的光通信接口,这可能导致出现类似“可升级”产品,这些产品的处理方式可能就像高性能RAM套件一样灵活和高效。
所谓的HMC,是一项由美光和三星最早在本世纪初开发的技术,混合存储立方体( HMC ) 是一种高性能计算机随机存取存储器(RAM) 接口,适用于基于硅通孔(TSV) 的堆叠 DRAM 内存。其在最开始的设计指出,就是为了与不兼容的竞争对手接口高带宽内存(HBM) 竞争。
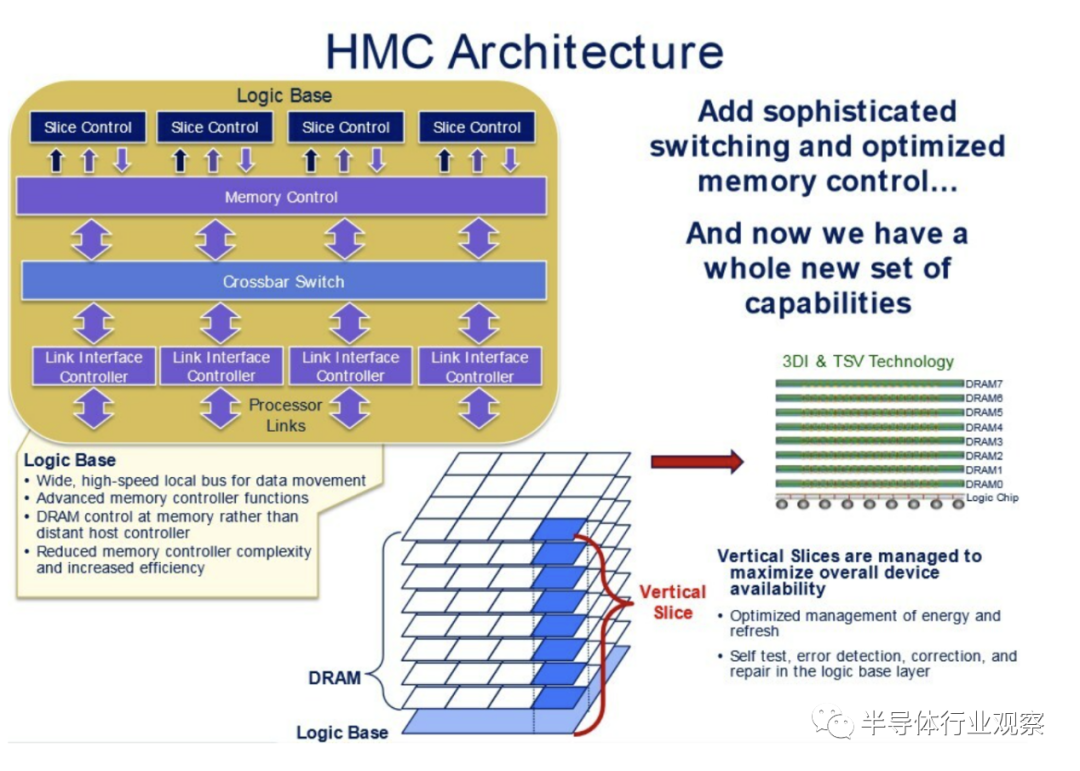
相关资料显示,HMC的主要目标之一是去除现代 DIMM 的重复控制逻辑,简化设计,以 3D 配置连接整个堆栈,然后使用单个控制逻辑层来处理所有读/写流量。
混合内存立方体的承诺是一种专门设计用于响应多核场景并以更高的带宽和更低的总体延迟提供数据的架构。HMC 极具前瞻性,它解决了许多与百亿亿次计算相关的问题,但它也依赖于半导体制造的一些深刻改进。这是最昂贵的新标准,也是唯一未经 JEDEC 批准的标准。
写在最后
总的来说,从Chiplet到异构集成,再到裸片堆叠,这些先进封装技术正逐步解决传统芯片缩放遇到的难题,同时也为未来的芯片设计提供了更多的灵活性和高效性。同时随着互连技术的演进,特别是光互连技术的加入,预计将进一步促进封装技术的进步,为行业带来更低功耗、更高性能的计算解决方案。
HBM及其相关封装技术将继续在高性能计算领域扮演重要角色,推动技术发展,满足市场对高效率和高性能计算需求的不断增长。
本文编选自“半导体行业观察”;智通财经编辑:叶志远。

 扫码下载智通APP
扫码下载智通APP