
英伟达(NVDA.US)被弯道超车?
据不完全统计,目前半导体行业已开发出约 1000 种封装类型,按互连类型来划分,其中包括了引线键合、倒装芯片、晶圆级封装 (WLP) 和硅通孔 (TSV)等,无数个die通过互联器件相连接,构成了如今日渐繁盛的封装市场。
其中的先进封装,成为了近两年最受关注和欢迎的领域,先进制程进展越缓慢,它的重要性就愈发突出, AMD、英特尔和英伟达这传统的“御三家”纷纷涉足,从2D封装转战2.5D封装,还向3D封装这座高峰发起了挑战。
2023年6月,AMD在旧金山正式推出了MI300X与MI300A两款AI加速器, 其中MI300X 采用了8 XCD,4个IO die,8个HBM3堆栈,高达256MB的AMD Infinity Cache和3.5D封装的设计,支持 FP8 和稀疏性等新数学格式,是一款全部面向 AI 和 HPC 工作负载的设计,而它的晶体管也达到了1530 亿颗,成为了 AMD 迄今为止制造的最大芯片。

AMD表示,MI300X 在人工智能推理工作负载中的性能比英伟达 H100高出1.6倍,在训练工作中的性能与 H100相当,从而为业界提供了亟需的高性能替代品,以取代英伟达的GPU。此外,这些加速器的 HBM3 内存容量也是英伟达 GPU 的两倍多,达到惊人的 192 GB,使其 MI300X 平台能够支持每个系统两倍多的 LLM,并能运行比 H100 HGX 更大的模型。
最受瞩目的当然还是AMD所宣称的3.5D封装,AMD表示,通过引入3D混合键合和2.5D的硅中介层,实现了全新的“3.5D封装”技术。
AMD 高级副总裁兼企业研究员 Sam Naffziger 表示:“这是真正令人惊叹的硅堆栈,提供了业界目前已知的最高密度性能。这一集成采用了台积电的两种技术,即 SoIC(集成芯片系统)和 CoWoS(晶片基板芯片)。前者(SoIC)使用混合键合技术将较小的芯片堆叠在较大的芯片之上,无需焊料就能直接连接每个芯片上的铜垫,其帮助高速缓冲存储V-Cache 芯片堆叠在最高端的 CPU 芯片上,而后者(CoWos)将芯片堆叠在一块更大的硅片上,这块硅片被称为内插板(interposer),用于容纳高密度互连。”
当英伟达还在H200中使用台积电CoWoS的2.5D封装时,AMD却率先一步,实现了台积电SoIC 3D封装和CoWoS 2.5D封装的结合,而它更早之前对Chiplet的布局,似乎早已为这次弯道超车做足了准备。
搭积木一样造芯片
首先我们来回顾一下MI300X和MI300A的具体架构,根据AMD官方的解释,MI300系列采用了台积电的 3D 混合键合 SoIC(集成电路上硅)技术,在四个底层 I/O 芯片之上对各种计算元件进行 3D 堆叠,无论是 CPU CCD(核心计算芯片)还是 GPU XCD。每个 I/O 芯片可以容纳两个 XCD 或三个 CCD。每个 CCD 与现有 EPYC 芯片中使用的 CCD 相同,每个 CCD 拥有八个超线程 Zen 4 核心。MI300A 使用了其中的三个 CCD 和六个 XCD,而 MI300X 使用了八个 XCD。
所谓 XCD,是AMD在GPU中负责计算的Chiplet,在MI 300X上,8个XCD包含了304 个CDNA 3 计算单元,那就意味着每个计算单元包含了34个CU。作为对比,AMD MI 250X 拥有220个CU,这是一个较大的飞跃。
而HBM 堆栈则采用了 2.5D 封装技术的标准中介层进行连接,每个 I/O 芯片都包含一个 32 通道 HBM3 内存控制器,用于托管 8 个 HBM 堆栈中的两个,从而为该设备提供了总共 128 个 16 位内存通道。MI300X 采用 12Hi HBM3 堆栈,容量为 192GB,而 MI300A 使用 8Hi 堆栈,容量为 128GB。
具体而言,AMD 的 CPU CCD 通过 3D 混合键合到底层 I/O 芯片,通过利用标准 2.5D 封装的GMI3接口进行通信,AMD 为此添加了一个新的焊盘通孔接口,可绕过 GMI3 链路,从而提供垂直堆叠芯片所需的 TSV。
5nm XCD GPU 芯片标志着 AMD GPU 设计的全面芯片化,XCD 和 IOD 具有硬件辅助机制,可将作业分解为更小的部分、分派它们并保持它们同步,从而减少主机系统开销,这些单元还具有硬件辅助的缓存一致性。
为了MI300系列封装的这一小步,AMD准备了多年的时间,最早的起源可以追溯到1965年,当时AMD工程师以 "芯片组 "概念为基础,开发出一种将每个大芯片拆分成小块的设计。

在和英特尔的CPU竞争中,推土机架构的失败让AMD的处境岌岌可危,它亟需一个低成本的解决方案来与英特尔更先进的架构竞争,Zen应运而生,新一代Ryzen处理器采用芯片组或 MCM(多芯片模块)架构,标志着整个 PC 和芯片制造行业的彻底转变。
Zen初代架构相对简单,采用了SoC 设计,从内核到 I/O 和控制器的所有内容都位于同一芯片上,同时引入了 CCX 概念,其中 CPU 核心被分为四核单元,并使用无限高速缓存进行组合,由两个四核 CCX 组成一块芯片,不过消费级仍然是单芯片的设计。
而Zen+ 的情况基本上保持不变(采用了更先进节点),但 Zen 2 是一个重大升级,这是第一个基于Chiplet的消费类 CPU 设计,具有两个计算芯片或CCD加一个 I/O 芯片。AMD 在 Ryzen 9 上添加了第二个 CCD,其核心数量在消费者领域前所未见。
Zen 3进一步完善了Chiplet设计,取消了CCX并将八个核心和32MB缓存合并到一个统一的CCD中,这大大减少了缓存延迟并简化了内存子系统,AMD 锐龙处理器首次提供了比对手英特尔更好的游戏性能。Zen 4 除了缩小 CCD 设计外,没有对 CCD 设计做出显着改变。
而EPYC系列中,第一代 AMD EPYC 处理器中基于四个复制的小芯片。每个处理器都有 8 个“Zen”CPU 内核、2 个 DDR4 内存通道和 32 个 PCIe 通道,以满足性能目标,AMD 必须为四个小芯片之间的 Infinity Fabric 互连提供一些额外的空间。
第二代EPYC的第一个Chiplet称为I/O die(IOD),采用12nm工艺,包含8个DDR4内存通道,128个PCIe gen4 I/O通道以及其他I/O(如USB和SATA, SoC数据结构,和其他系统级功能)。第二个Chiplet则是复合核心die(CCD),采用7nm工艺。在实际产品中,AMD将一个IOD与多达8个ccd组装在一起,每个CCD提供8个Zen 2 CPU内核,因而可以一次提供64个内核。
第三代EPYC上,AMD提供多达64个核心和128个线程,采用AMD最新的Zen 3核心。该处理器设计有八个Chiplet,每个Chiplet有八个核心,这次Chiplet中的所有八个核心都是连接的,从而实现了有效的双 L3 缓存设计,以实现较低的整体缓存延迟结构。
第四代EPYC中,AMD在原来的架构上采用多达 12 个 5 纳米复杂核心芯片 (CCD) 的小芯片设计,其中I/O 芯片采用 6nm 工艺技术,而其周围的 CCD 则采用 5nm 工艺。每个芯片具有 32MB 的 L3 缓存和 1 MB 的 L2 缓存。
这些CPU最终为MI300系列的Chiplet铺平了技术方面的道路。
2021年1月,AMD申请并通过了一项MCM GPU Chiplet 设计的专利,AMD在美国专利商标局公开了一项标题为“使用高带宽交联的 GPU Chiplets”的专利,专利号为“US 2020/0409859 A1”,在专利描述中,AMD概述了Chiplet设计中的图形芯片未来的样子,GPU Chiplet应直接与 CPU 通信,而其他小Chiplet通过无源、高带宽交叉链路相互通信,并作为片上系统 (SoC) 布置在相应的中介层上。
2023年11月,AMD又公开了一项关于Chiplet 设计的专利,其描述了一种与现有芯片布局截然不同的 GPU 设计,即在大型主 GPU 芯片周围分布大量内存缓存芯片(MCD),其描述了一种将几何工作量分配到多个芯片上的系统,所有芯片并行工作。此外,没有一个 "中央芯片 "会将工作分配给下属芯片,因为它们都将独立运行。该专利表明,AMD 正在探索用芯片组来制造 GCD,而不仅仅是一块巨大的硅片。
从消费领域到超算领域,再到AI领域, AMD利用Chiplet掀起了一场红色风暴,而为这场风暴不断提供助力的,正是来自台积电的先进封装技术。
AMD背后的人
在接受IEEE Spectrum采访时,AMD产品技术架构师Sam Naffziger讲到:“五六年前,我们开始研发 EPYC 和 Ryzen CPU 系列。当时,我们进行了广泛的研究,以找到最适合连接芯片的封装技术。这是一个涉及成本、性能、带宽密度、功耗和制造能力的复杂方程式。想出好的封装技术相对容易,但要真正做到大批量、低成本地生产,则完全是两码事。”
2011年,台积电首次开发了2.5D封装 CoWoS,随即就被赛灵思的高端 FPGA 采用,但由于其价格过于昂贵,在封装市场上迟迟打不开局面,直到AI浪潮的席卷全球,英伟达、AMD、谷歌、英特尔纷纷抛来了橄榄枝,将CoWoS推上了最热门先进封装的宝座。
下面是台积电的 CoWoS(晶圆基板上芯片)封装示意图。CoWoS 允许在单个封装上集成多个芯片或裸片。这样就能将不同类型的芯片(如处理器、内存和图形芯片)集成到单个封装中,从而提高性能、降低功耗并缩小外形尺寸。多个芯片通过硅通孔(TSV)垂直堆叠,并用微凸块互连。与传统的2D封装相比,这种堆叠方法可以缩短互连长度、降低功耗并提高信号完整性。
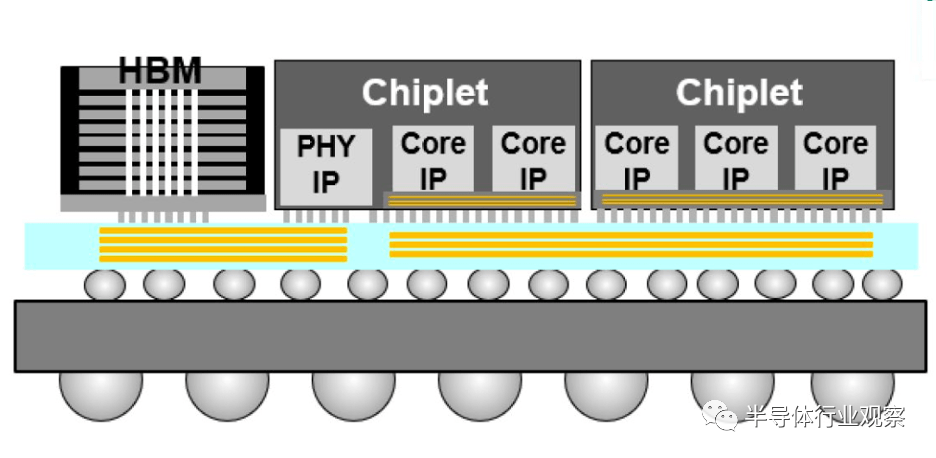
CoWoS在AMD的Chiplet上出力不少,通过将大型单片芯片划分为较小的芯片组,设计人员可以专注于优化每个芯片组的特定功能。,可实现更好的电源管理、更高的时钟速度和更高的每瓦性能,同时还有助于将这些高性能芯片与内存等其他组件集成到一个封装中,从而进一步提高系统性能。
CoWoS为之后的3D封装提供了宝贵经验,2018年,台积电推出了SoIC 技术,其作为一种创新的多晶片堆叠技术,主要是针对 10nm 以下的工艺技术进行晶圆级接合,与CoWoS技术相比,SoIC可提供更高的封装密度、更小的键合间隔,还可以与CoWoS/InFo共用,实现多个Chiplet集成。
在IEDM 会议上,台积电副总裁介绍了该公司 SoIC 路线图的更多细节。根据路线图,台积电首先采用目前可用的 9μm 键合间距。然后,它计划推出 6μm 间距,接着是 4.5μm 和 3μm。换而言之,台积电希望每两年左右推出一种新的键距,每一代产品的缩放比例提高 70%。
他还用AMD的处理器作为SoIC应用的例子,AMD 设计了基于 7nm 工艺的处理器和 SRAM,然后交由台积电生产,最后以 9μm 键合间距的SoIC技术来连接芯片。
这里提到的,正是AMD在2021年推出的代号为Milan-X的EPYC处理器里加入的3D V-Cache缓存,这也是世界上首款采用3D芯片堆叠的数据中心处理器。
AMD 表示,3D V-Cache 在当前第三代 EPYC CPU 每个计算芯片 32 MB 的 SRAM 基础上又增加了 64 MB,使 Milan-X 每个计算芯片的三级缓存达到 96 MB,由于 Milan-X 处理器架构中最多有 8 个计算芯片,因此 CPU 中共享的 L3 缓存最多可达 768 MB,额外的 L3 缓存可以缓解内存带宽压力并减少延迟,从而显着提高应用程序性能。
能实现这一步,台积电的 SoIC 技术功不可没,其将 V-Cache 中的互连永久绑定到 CPU,缩小了芯片之间的距离,从而实现 2 TB/s 的通信带宽,与第三代 EPYC CPU 使用的 2D 小芯片封装相比,Milan-X CPU 中的互连的每比特能耗仅为三分之一,互连密度提高了 200 倍,功效提高了三倍。
这一项技术后续也被下放到了Ryzen 7 5800X3D处理器之中,开始在消费市场中大展身手,包括最新的Ryzen 9 7950X3D,同样用到了3D V-Cache的技术。
2023年,台积电在北美技术论坛上着重介绍了全新的3DFabric技术,其主要由先进封装、3D芯片堆叠和设计等三部分组成。通过先进封装,可以在单一封装中置入更多处理器及存储器,从而提升运算效能;在设计支持上,台积电推出开放式标准设计语言的最新版本,协助芯片设计人员处理复杂大型芯片。
2011年至2023年,台积电十余年的封装技术演进让AMD的Chiplet梦想终于得以实现,而MI300系列也正是建立在最新的3DFabric基础之上,将台积电SoIC 前端技术与 CoWoS后端技术相集成,堪称量产先进封装技术的集大成者。
蓝色巨人的封装版图
对于英特尔来说,封装同样是它发展的重心之一,而且与AMD不同的是,英特尔选择了自己搞封装,力图掌握芯片研发生产应用的全流程。
英特尔对标台积电CoWoS的2.5D封装技术被称为EMIB, 2017年正式应用于产品,英特尔的数据中心处理器Sapphire Rapid就是采用的这项技术;第一代的3D IC封装则称为Foveros,2019年时已用于英特尔计算机处理器Lakefield。
EMIB最大特色就是通过硅桥(Sillicon Bridge),从下方来连接存储器(HBM)和运算等各种芯片(die)。也因为硅桥会埋在基板(substrate)中并连接芯片,让存储器和运算芯片能直接相连,加快芯片本身的能效。
Foveros则是3D堆栈,将存储器、运算和架构等不同功能的芯片组堆栈起来后,运用铜线穿透每一层,达到连接的效果,最后,工厂会将已经堆栈好的芯片送到封装厂座组装,将铜线与电路板上的电路做接合。
2022年,英特尔首次将下2.5D和3D封装技术融合在一起,命名为Co-EMIB,这是一个将EMIB和Foveros技术相结合的创新应用,能够让两个或多个Foveros元件互连,并且基本达到单芯片的性能水准,藉由这一项技术,推出了当时晶体管规模最大的SoC——Ponte Vecchio,主要面向高性计算市场。
每颗 Ponte Vecchio 处理器实际上都是 使用英特尔Co-EMIB 连接在一起的两个Chiplet的镜像集,Co-EMIB 在两个 3D Chiplet堆栈之间形成高密度互连的桥梁,桥本身是嵌入封装有机基板中的一小块硅。硅上的互连线可以比有机基板上的互连线更窄。Ponte Vecchio 与封装基板的普通连接间隔为 100 微米,而 Co-EMIB 芯片中的连接密度几乎是其两倍,Co-EMIB 芯片还将高带宽存储器 (HBM) 和 Xe Link I/O Chiplet连接到“基础硅”(最大的Chiplet),其他芯片则堆叠在该“基础硅”上。
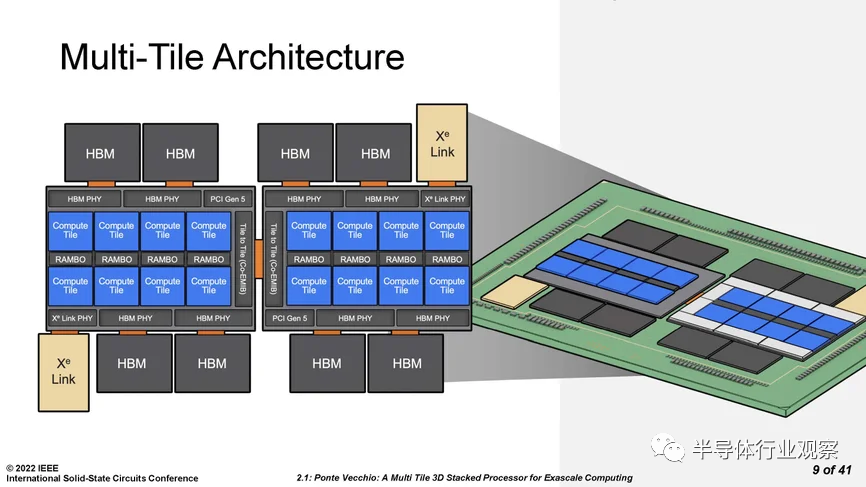
基础芯片还使用了英特尔的 3D 堆叠技术,称为 Foveros,该技术在两个芯片之间建立了密集的芯片到芯片垂直连接阵列。这些连接仅相距 36 微米,并通过“面对面”连接芯片来实现;也就是说,一个芯片的顶部粘合到另一个芯片的顶部。信号和电源通过TSV硅通孔进入该堆栈,硅通孔是相当宽的垂直互连,直接穿过大部分硅。Ponte Vecchio 上使用的 Foveros 技术是对用于制造英特尔Lakefield 移动处理器的技术的改进,信号连接密度增加了一倍。
做到这一点并不容易,英特尔院士Wilfred Gomes表示,这需要在产量管理、时钟电路、热调节和功率传输方面进行创新。例如,英特尔工程师选择为处理器提供高于正常水平的电压(1.8 伏),以便降低电流,简化封装,基片中的电路将电压降低到接近 0.7 伏,以便在计算芯片上使用,而且每个计算芯片都必须在基片中拥有自己的电源域。
对于英特尔来说,Ponte Vecchio将它目前已有的先进封装技术推到了巅峰,与AMD的MI300系列相比,也未逊色多少,可谓是如今先进封装的红蓝双星。
实际上,英特尔虽然在先进制程上略落后于台积电,但在先进封装却与台积电不相上下。英特尔表示,自己灵活的代工服务,允许客户混合搭配其晶圆制造和封装产品,作为老牌厂商的它,晶圆封装厂分散在世界各地,可以利用地理优势来扩大产能和服务。
英特尔CEO Pat Gelsinge在接受采访时也表示,英特尔拥有下一代内存架构的先进能力,以及3D 堆叠的优势,既能用于Chiplet,也能用于人工智能和高性能服务器的超大封装,未来我们将把这些技术应用到产品中,同时也将展示给代工厂(IFS)的客户、
为什么是Chiplet?
在看完AMD、英特尔以及台积电的技术历程后,相信许多人都会有一个疑问,为什么他们如此执着于3D封装和Chiplet呢?
原因源自半导体行业内部的需求,摩尔定律的出现,让不断提高的设备集成度能够继续适应相同的物理尺寸,光刻缩小可以使构建块缩小 30%,那么就可以在不增加芯片尺寸的情况下增加 42% 的电路。
但并非所有半导体器件都能享受这一红利,例如可以包含模拟电路的 I/O,其扩展速度约为逻辑的一半,这就让人不得不寻找新的出路。而且光刻缩小的成本也不便宜,采用 7nm 工艺加工的晶圆成本高于采用 14nm 工艺加工的晶圆成本,5nm 工艺的成本高于 7nm 工艺,依此类推……随着晶圆价格的上涨,Chiplet往往比单片更加经济实惠。
此外,由于新芯片设计需要设计和工程资源,并且由于新节点的复杂性不断增加,每个新工艺节点的新设计的典型成本也随之增加,这一的情况进一步激励人们创建可重复使用的设计。
Chiplet设计理念使这成为可能,因为只需改变芯片的数量和组合即可实现新的产品配置,通过将单个小芯片集成到 1、2、3 和 4 芯片配置中,可以从单个流片创建 4 种不同的处理器品种,而如果想把它们整合进一块芯片中,就需要 4 次单独的流片。
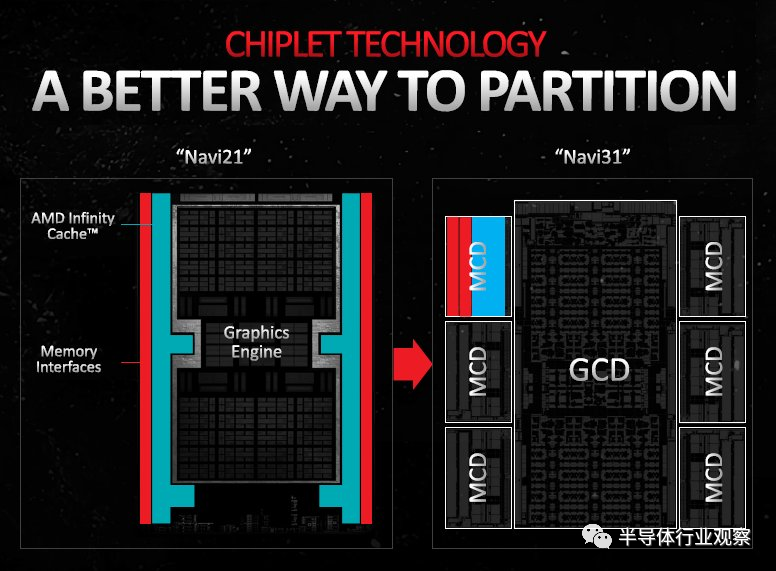
AMD 在其关于新款 Radeon RX 7900 系列 "Navi 31 "图形处理器的技术演示中,详细解释了为什么必须为高端图形处理器采用芯片组路线。
事实上,AMD 近十年里的 Radeon GPU 与CPU相比,不管是利润还是收入都不容乐观,在面临英伟达竞争的情况下,降低制造成本的必要性愈发突出,随着 GeForce "Ada Lovelace "一代的推出,英伟达继续押注在单片硅 GPU 上,即使是最大的 "AD102 "芯片也还是单片 GPU,这为 AMD 提供了一个降低 GPU 制造成本的机会。
Chiplet让AMD其能够和英伟达展开价格战,拿下更多的市场份额。最典型的例子是,AMD 对 Radeon RX 7900 XTX 和 RX 7900 XT 分别采用了相对激进的999美元和899美元定价,根据AMD 的官网数据,这两款产品有能力与英伟达 1199 美元的 RTX 4080 一决高下,在某些情况下,甚至有可能与 1599 美元的 RTX 4090 展开较量。
事实上,这就是Chiplet的最显著的优点之一,通过使用Chiplet,AMD可以快速提高良率并简化设计/验证,同时可以为每个小芯片选择最佳工艺。逻辑部分可以采用尖端工艺制造,大容量SRAM可以使用7nm左右的工艺制造,而I/O和外围电路可以使用12nm或28nm左右的工艺制造,从而减少了设计和制造成本。
此外,Chiplet也能帮助它轻松制造衍生类型,例如相同逻辑但不同外围电路,或相同外围电路但不同逻辑,而且可以混合使用来自不同制造商的小芯片,而不是局限在单个制造商上。
AMD如此,英特尔也不外乎是,AMD仰赖台积电已有的技术,全力研究芯片架构设计,英特尔就要稍微吃力一点,一方面研究先进制程和封装,另外一方面也要着手芯片与Chiplet的迭代改进,两家甚至还在封装上打起了擂台赛。
如今去评判比赛的胜负已经不重要了,因为3D封装与Chiplet逐渐从数据中心和AI加速器走向消费市场的PC处理器,最终惠及笔记本与手机,成为了大家认定的新趋势。
写在最后
与AMD和英特尔相比,英伟达在3D封装以及Chiplet上却显得如此“迟钝”。
2017年6月英伟达发表论文《MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability》提出了MCM设计,其基本可以看成是如今的Chiplet。
但英伟达一直未将这一设计付诸于实践中,反而在2021年12月发表了一篇名为《GPU Domain Specialization via Composable On-Package Architecture》的论文,其中所提出的COPA-GPU架构,实际只是单独分离了L2缓存,这也就是说,英伟达会在未来继续坚持Monolithic单一光刻设计。
英伟达坚持大芯片的原因其实很简单,die与die之间通讯带宽永远无法和monolithic内部的通讯带宽相比,Chiplet也许不适合高AI算力场合,更适合在CPU领域中大展拳脚,2022年英伟达发布的Grace CPU Superchip,就通过NVLink-C2C技术实现芯片高速互连,该芯片还遵循由业界共同制定的Chiplet互连规范UCIe。
在Chiplet上的谨慎,也让英伟达与3D封装没了缘分,虽然英伟达目前是台积电2.5D封装CoWoS的最大客户之一,但SoIC的客户里暂时还不包括它,也让它成了御三家里最晚拥抱这项先进技术的一家了。
伴随着Chiplet的高速发展,英伟达也可能在未来开始拥抱这一设计理念,今年的爆料人士Kopite7kimi称,英伟达面向高性能计算(HPC)和人工智能(AI)客户的下一代Blackwell GB100 GPU将全面采用Chiplet设计。
如今AMD在AI芯片上先行一步,利用Chiplet和3.5D封装打造了更大更强的MI300X,英特尔也已经全面拥抱Chiplet和3D封装,英伟达虽然依旧坐拥庞大的AI市场,但它的宝座却出现了一道微不可察的裂缝,红蓝绿这三家,谁能在芯片封装上掌握真正的话语权呢?
本文转自" 半导体行业观察",智通财经编辑:叶志远。

 扫码下载智通APP
扫码下载智通APP